最近由于工作需要,也可以说是为了加快工作效率,于是用Java编写了一个可以批量截取网页列表详细页面内某些信息的程序,例如希望截取详细页面内的邮箱地址和联系电话,那就可以通过正则表达式配置好本程序的配置文件,然后按照程序的步骤将列表页URL地址粘贴在适当位置并作一定调整,就可以成功地进行批量截取网页详细页面的指定信息了。
具体操作步骤如下:
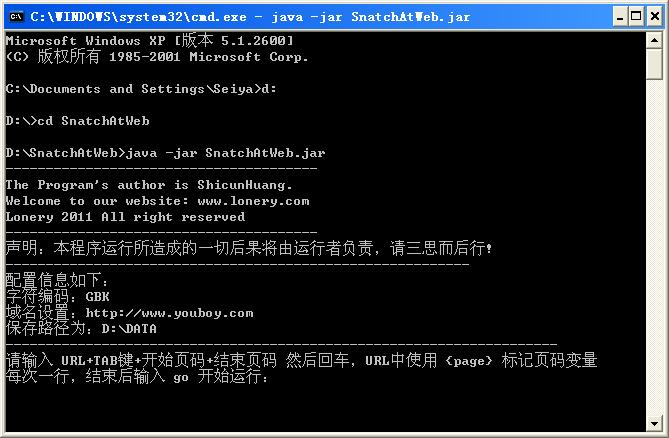
1、进入命令行,然后切换到程序所在的目录,输入java –jar SnatchAtWeb.jar运行程序;如下图所示:
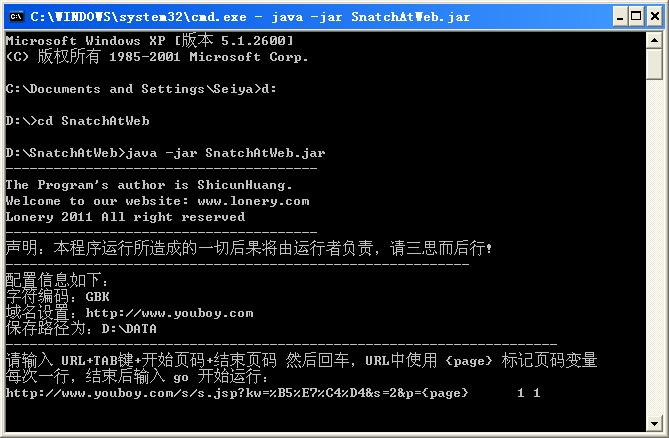
2、然后输入要截取信息的跳转列表页URL,并用{page}来替换URL中的动态页码,然后输入一个TAB键加上开始页码,在输入一个空格键和结束页码,然后回车,这里您可以重复之前的动作,添加若干行列表页URL地址,并以相同的方式配置好,至于最多能添加多少个URL地址,我还没有测试过,请大家自己试试,这里以一呼百应为例进行测试;
例如:您要截取的列表页URL为
http://www.youboy.com/s/s.jsp?kw=%B5%E7%C4%D4&s=2&p=1
最后面的1为动态页码,则可以将此URL设置为
http://www.youboy.com/s/s.jsp?kw=%B5%E7%C4%D4&s=2&p={page}
如果不用{page}来替换动态页码,则程序会只截取该URL的当页。
如下图所示:
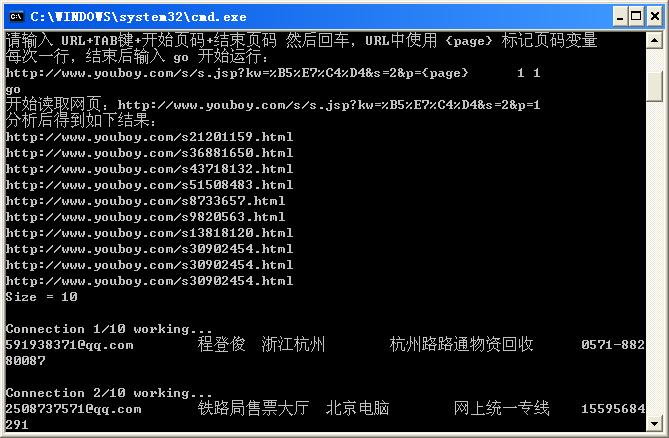
3、配置好所有的列表页URL之后,输入go运行程序,程序将会读取列表页URL中指定的详细页面URL地址,然后跳转到详细页面进行内容截取,如下图所示:
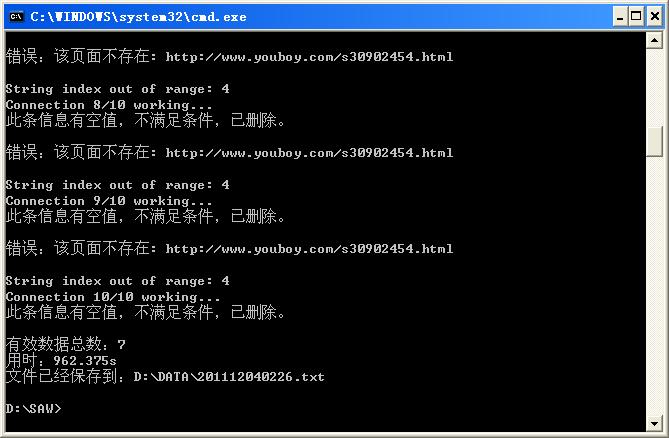
4、程序运行结束后会输出有效数据总数,即找到的数据行数(如果找到的信息中有空字段,程序将会自动删除该行),使用总时间和文件保存路径,以便于您查看该文件。
5、获取信息处理:本程序截取到的数据会一般会包含许多重复信息,原因不是由程序bug造成,而是网站列表页中会有重复信息的原因,处理此问题的方法可以使用Office 2007及以上版本的Excel软件,将结果文件导入到Excel中,导入时使用TAB键分隔每行的信息,然后使用删除重复项功能并设定某一列为参考将重复内容删除即可。
6、配置文件说明:
第一行size为设置所截取的信息类数,及表示url列表匹配下一行开始至end结束之间的类别数(行数,以一行一个类别配置),size要与类别数匹配,否则可能会出现错误。,此项为必填项,不能为空。
第二行charset为设置所截取网页的编码格式,此项为可选项,不使用可以留空,及等号=后不写任何内容即可,但不可以删除此行。
第三行domainName为域名及不全列表url的地址信息,例如有的网站获取到的url只有最后一个文件的文件名,或者是从根目录开始的地址,则需要进行设置以补全url,否则将截取不到信息,此项为可选项,不使用可以留空,及等号=后不写任何内容即可,但不可以删除此行。
第四行savePath为保存文件的路径,此项为可选项,留空则使用默认路径(D:JavaData日期文件夹),此项为可选项,但不可以删除此行。
第五行url列表匹配为配置url列表也的正则表达式匹配,注意“url列表匹配”之后要有4个“,”,及(url列表匹配,,,,)每两个“,”之间填写一正则表达式,顺序分别为,全匹配,左清除匹配,右清除匹配。(必填)
第六行至结束标记end之间为内容页中要匹配截取的网页内容,每一行表示一个字段类别。配置同“url列表匹配”。不同之处在于,第一个字段,及第一个“,”号之前的为字段名,只能使用字母,不能为空(必填)
最后一个为end标记,不可缺省,当读取到end后,程序将不再读取信息,所以end一下的内容不会被读取到程序中。
7、最后说明和声明:如果您需要本程序,那么您可以通过发送电子邮件的方式与我联系,我将通过邮件附件的方式将本程序的发行版发送给您,要是您想重新编译此程序,则可以向我提出申请,我会将本程序的源代码一起发送给你,但是您必须在再发行版本中包含我们的网站和版权信息等,只要符合自由软件协议即可。
本程序为我自己编写,如果您真要使用本程序,请您自行负责程序运行所造成的一切后果,我及本站将不负任何责任,只是作为个人使用而编写而已。